Weakly Supervised Learning: Introduction and Best Practices
“How to label the unlabeled data”
On 27th June 2019 at Softec S.p.A., Data Science Milan has organized a meetup about Weakly Supervised Learning topic. In recent years Machine Learning has grown exponentially, but these models are dependent on massive sets of hand-labeled training data. These hand-labeled training sets are expensive and time-consuming to create, especially when domain expertise is required and for these reasons, practitioners have increasingly been turning to weaker forms of supervision.

“Weakly Supervised Learning: Introduction and Best Practices”, by Kristina Khvatova, Software Engineer at Softec S.p.A.
Kristina explained what Weakly Supervised Learning means and what kind of strategies are used to get more labeled training data. Weakly supervised learning is an umbrella covering several processes which attempt to build predictive models by learning with weak supervision. It consists on an approach to inject domain expertise, functions which label data based on new generated training data.
There are three typical types of weak supervision: incomplete supervision when only a subset of training data are labelled; inexact supervision when the training data are given with labels but not as exact as desidered and inaccurate supervision when in the training data there are some labels with mistakes.
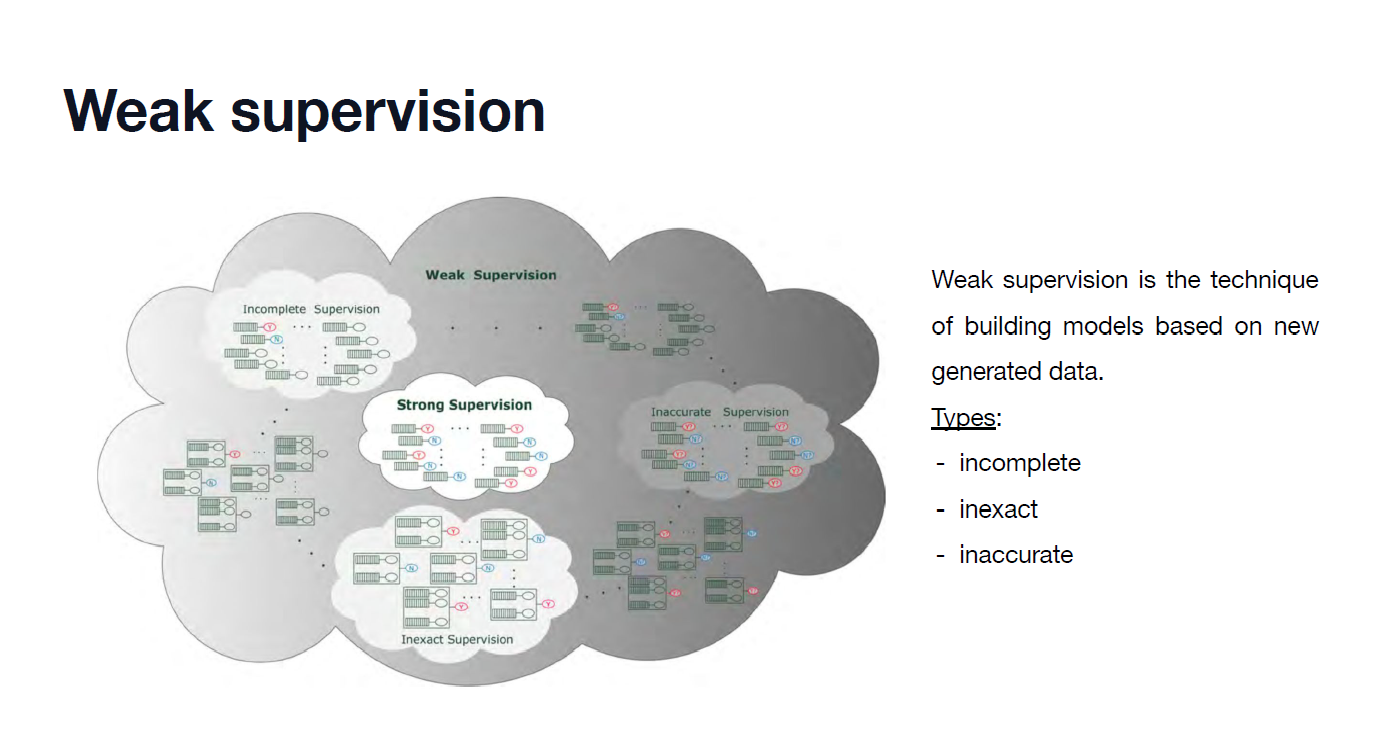
Let’s have a look at the strategies used in these types of weak supervision.
In the incomplete supervision can be adopted active learning or semi-supervised learning; depending by the human intervention. In active learning is used a domain expert to get labels of unlabeled instances and assumes that the labeling cost depends only by the number of queries, so the goal is to minimize the number of queries.
On the other hand semi-supervised learning try to exploit unlabeled instances without human intervention with some approaches: generative models, label propagation and TSVM.
Generative methods assume that both labeled and unlabeled instances belong to the same model: gaussian mixture distribution. In this way labels of unlabeled data can be treated as missing values of model parameters.
Label propagation or disagreement-based methods generate multiple models and let learners to teach each other to exploit unlabeled data; it can be viewed as a combination between semi-supervised learning and active learning.
Another algorithm is transductive support vector machine (TSVM). While SVM looks for a decision boundary (finding an hyperplane) with maximal margin over the labeled data, TSVM label the unlabeled instances looking for a decision boundary with maximal margin over all of the data.
In the inexact supervision are used Deep Learning and specially CNN (Convolutional Neural Network). Deep Learning due to their impressive ability to automatically learn representations across many domains and tasks, have largely replaced the task of feature engineering. For this item can be used multi-instance learning, more precisely, the training set consists of labeled “bags”, each of which is a collection of unlabeled instances. A bag is positively labeled if at least one instance in it is positive, and is negatively labeled if all instances in it are negative. The goal is to predict the labels of unseen bags.
In the innacurate supervision the approach is to use several learners (ensemble) to identify unlabeled examples and then check it with training data trying to make some correction. An helpful strategy is the crowdsourcing, more precisely, unlabeled instances are outsourced to a large group of workers to label. It’s a cost-saving way to collect labels for training data.
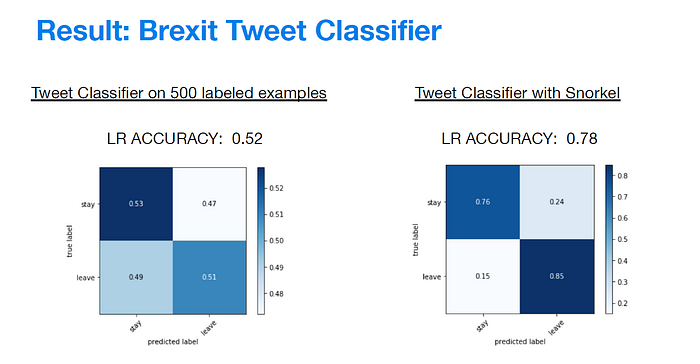
At this step Kristina explained a practical case study: a Brexit Tweet Classifier collecting 3184 unlabeled data and comparing results using a Linear Regression from a Tweet Classifier on 500 labeled examples and a Twitter Classifier with Snorkel. With the first one has obtained 52% of Accuracy, with the second one 78% of Accuracy. Look at the code.
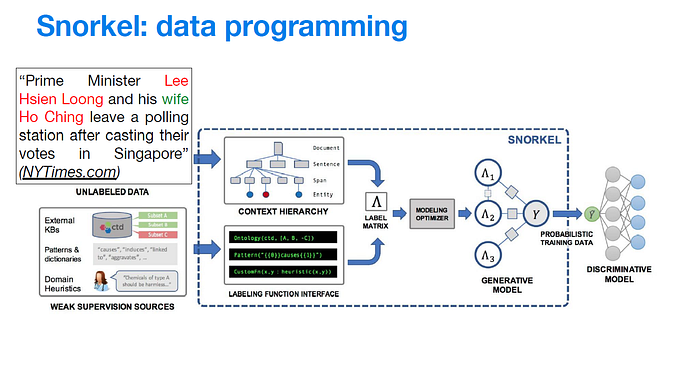
Snorkel is a system that works on the development of structured data or data extraction for domains in which large labeled training set are not available. It’s based around the new data programming paradigm, in which the developer is focused on writing a set of labeling functions, that programmatically label data. Labels produced are noisy and Snorkel try to model this noise by learning a generative model of the labeling process, choosing labels more accurate and using this new label set to train an end discriminative model with higher accuracy. Since the supervision is provided as functions, it allows to scale huge amount of unlabeled data.
References:
-https://github.com/KKhvatova/Weakly_Supervised_Learning
-https://academic.oup.com/nsr/article/5/1/44/4093912
-https://arxiv.org/abs/1711.10160
-http://ai.stanford.edu/blog/weak-supervision/
-https://dawn.cs.stanford.edu/2017/05/08/snorkel/
-https://github.com/HazyResearch/Snorkel
-https://github.com/HazyResearch/metal
Written by Claudio G. Giancaterino
